
随着AI智能体应用迎来爆发式增长,PC产业正迎来数十年一遇的颠覆性变革,传统电脑硬件的产品逻辑、使用场景伴随端侧大模型落地迎来重构,超级Agent PC正式登上行业舞台。在这一轮产业变革中,AMD凭借前瞻性研判早早落地锐龙AI Max系列产品线,NVIDIA则在时隔一年半后发布了RTX Spark入局角逐。两大巨头同台发力不仅印证端侧AI PC巨大的市场潜力,也拉开了X86与ARM两大架构在本地AI赛道的正面竞争。
AI从GPU云端推理迈入本地AI Agent新纪元
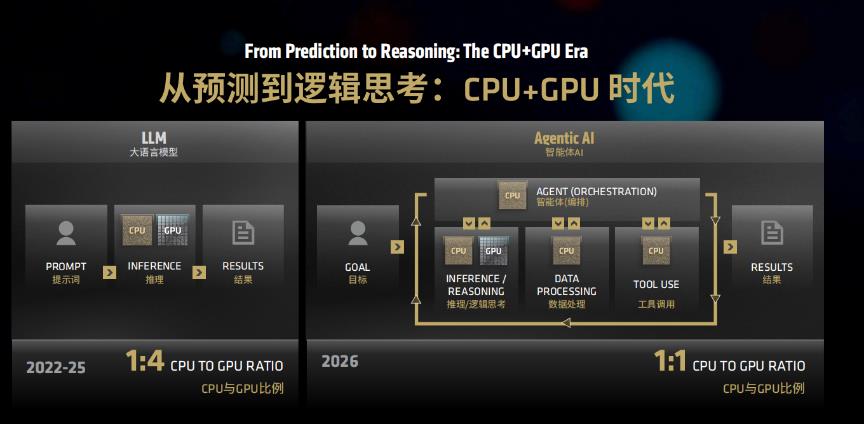
AMD表示,伴随OpenClaw、Hermes等智能体应用爆发式增长,全球AI产业正发生底层范式迁移。过去AI算力高度依赖云端数据中心GPU集群完成模型训练与推理,如今在AI Agent应用需求的驱动下,产业从单一GPU云端推理时代正式步入CPU+GPU协同运算的端侧本地智能体时代。
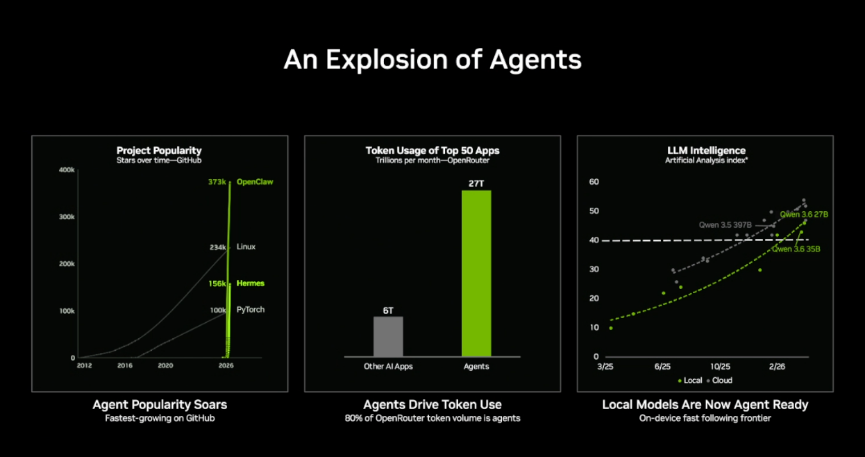
从NVIDIA提供的数据来看,当前80%的Token消耗量由各类AI智能体贡献,大模型参数规模持续走高、多智能体集群协同成为主流应用方向,云端Token使用成本暴涨也成为企业与开发者的普遍痛点,这些都催生了对本地高性能AI PC的刚需。由此可见AI Agent时代的到来已经是业界的共识。

根据高盛研报预测,至2030年,全球月度Token产出将达到12亿亿级别,单一企业规模化部署云端智能体的成本动辄每月数千万美元,本地端侧硬件落地大模型、分流云端算力成为行业必然选择。在此产业拐点下,AMD 与NVIDIA先后推出针对性的处理器产品,正式拉开超级Agent PC商业化落地的大幕,PC硬件的核心定位从传统办公娱乐工具,转变为可自主思考、自主完成复杂任务的个人AI协作终端。
战略远见:AMD率先锚定端侧AI赛道

早在2025年的CES展会,AMD便率先发布锐龙AI Max系列处理器,成为X86平台早期唯一能够支撑本地端运行超大参数大模型的芯片方案,可见其已经提前预判了AI智能体爆发的产业趋势,完成初代Strix Halo平台落地布局,相比NVIDIA刚刚才发布的RTX Spark提前一年多,充分印证了AMD在端侧AI与智能体主机赛道领先全行业的前瞻判断力。

AMD高级副总裁、客户端业务总经理Rahul Tikoo 在COMPUTEX 2026访谈中表示:“两年以来,我们几乎是这一领域唯一的参与者,我们在2025年CES上发布锐龙AI Max系列,产品瞄准创作者、工作站、游戏与新兴 AI 场景,经过一年多发展,已联合各大OEM落地超35款终端产品”。依托初代平台落地经验,AMD在2026年迭代第二代Gorgon Halo平台,计划于第三季度正式上市,最高统一内存规格升级至192GB,原生支持本地运行300B参数超大模型、并行部署多智能体集群,不仅远超英伟达N1X所能支持的规模,还能完整覆盖开发者、企业商用、消费级三大市场。
NVIDIA方面在2026年6月1日的GTC大会上正式发布了代号为N1X的RTX Spark 超级芯片,以Blackwell GPU + Arm架构的Grace CPU异构组合切入个人智能体PC赛道。在AMD验证端侧 AI市场价值、培育用户与生态一年多之后,NVIDIA才选择跟进入场。Rahul对此直言:“我们很高兴看到NVIDIA进入这一领域,NVIDIA实际上帮助整个行业验证了这一市场空间的价值,也让更多人意识到边缘AI和端侧AI是真实存在且具有实际意义的”。
与此同时,端侧AI市场体量足够庞大,完全可以容纳多家厂商同台竞争。Rahul明确表示,AI将实现全场景无处不在,只要存在数据就会有AI应用落地,目前整个端侧AI PC市场仍处于发展初期,未来将成长为巨型赛道,多元厂商共同入局有利于加速全产业链生态完善。AMD坦然接受行业竞争,依托自身产品与生态优势从容应对挑战。实际上,除NVIDIA外,高通骁龙C平台、英特尔Wildcat Lake、苹果M系列芯片均陆续布局定位入门的AI PC,进一步印证赛道扩容的长期逻辑。
产品深度对比:锐龙 AI Max+395 全平台兼容优势凸显

从硬件设计来看,锐龙AI Halo开发者平台使用的锐龙AI Max+ 395处理器基于成熟X86架构研发,依托数十年X86产业链积淀,可对现有Windows、主流Linux发行版实现一键原生适配,无需定制专属操作系统,现有海量Windows桌面软件、Linux开发工具、行业商用程序无需转译均可无缝迁移运行,拥有天然原生优势。
Rahul介绍,AMD长期与微软深度协同,针对微软正在迭代的Agentic OS(智能体操作系统)、AI Agent沙盒机制提前参与研发,相关系统优化功能上线时,AMD全系列产品可实现Day 0 第一时间适配,仅需OEM完成终端产品认证即可落地。
相比之下,NVIDIA的RTX Spark采用Arm架构的Grace CPU + Blackwell GPU 组合,受底层架构限制,无法兼容常规Windows,必须依赖微软专门定制的Windows on Arm专属版本,大量存量X86架构的Windows软件需要通过模拟层运行,不仅存在性能损耗,部分工业软件、商用外设驱动、传统开发工具仍面临兼容性缺失问题,跨系统部署成本远高于X86架构的锐龙 AI Halo开发者平台。

硬件配置上,锐龙AI Max+ 395搭载Zen5架构16核32线程CPU、40CU规格的RDNA3.5架构GPU、50 TOPS算力NPU,Strix Halo就已经最高可搭配128GB统一内存,新一代Gorgon Halo更是升级至最高192GB统一内存,原生硬件规格即可本地流畅运行300B超大参数大模型,支持6~10个智能体同步并行运算,实现智能体集群本地部署。

实测数据显示,运行120B GPT OSS模型时,锐龙AI Halo开发者平台推理速度较英伟达DGX Spark 高出7%;122B Qwen3.5模型领先 12%;35B Qwen3.6和30B GLM4.7 Flash分别领先4%、14%,在主流开源大模型推理场景全面占优。
NVIDIA RTX Spark方面,它拥有1 Petaflop FP4 AI算力、128GB 统一内存,没有搭载独立NPU,因此不能实现CPU + GPU + NPU三重异构算力协同,本地上限仅运行120B参数模型,在大模型承载上限方面低于锐龙的Halo家族。

产品线方面,AMD依靠统一X86平台架构打造全梯队产品矩阵,包括入门级锐龙 200系列、中端锐龙 AI 300系列、高端锐龙 AI 400系列、旗舰锐龙AI Max 300和新一代的锐龙AI Max PRO 400系列,同源架构让OEM厂商依托一套平台快速开发全价位产品,覆盖入门至高端工作站全细分市场,搭配AMD PRO技术,打通消费、中小企业、大型政企全渠道。
相比之下,RTX Spark产品定位高度集高端市场,产品仅面向高端创作者与专业开发者,缺少入门、中端产品线布局,难以下沉主流平价PC市场,对比AMD全平台产品布局存在明显短板。

软件生态部分,AMD以ROCm开源软件栈全框架Day0适配为核心构建软件生态,实现从云端数据中心到端侧PC全链路无缝兼容 PyTorch、ComfyUI、vLLM 等主流AI框架,大幅降低跨场景部署成本。针对锐龙 AI Halo开发者平台,AMD预置5套开箱即用Playbook开发手册,后续新增至 10 套,彻底解决开发者过去耗费数天调试Claw、各类 AI框架环境的痛点;软件完成优化和平台验证后,全量下放至合作伙伴全系列锐龙AI Max产品,普惠全品类终端用户。

开发者是AI Agent PC产业落地的核心根基,AMD在开发者扶持层面也落地实质性举措,构建从线下会议、云端资源、软硬件工具的全链条赋能体系,近期AMD 在上海成功举办AI开发者日,成为国内开发者生态建设关键里程碑。
Rahul在访谈中提及,AMD 高管、软件团队常态化对接全球数百名开发者,在多地举办开发者日,现场开放产品沙盒试验环境,让开发者免费实测锐龙AI全系列硬件,这就类似AMD在成熟游戏领域的 FSR生态合作经验,将深度协同开发者的基因复制至AI领域。
在落地细则上,加入AMD开发者计划即可免费申领云端算力Token、持续获取BKC最优配置软件更新、享受原厂技术团队一对一支持;OEM厂商同步推出标准化锐龙 AI Halo 硬件盒子,统一软件镜像,帮助开发者低成本批量部署本地AI节点。

从商业落地角度来看,锐龙 AI Halo 可以帮助企业大幅削减云端Claude Code等智能体工具的巨额 Token 开支,这一经济性优势快速收获政企CIO认可,倒逼OpenAI、Anthropic等闭源大模型厂商探索“云端 + 本地混合部署”新模式,为AMD平台拓展更大商用空间。
相较之下,NVIDIA虽凭借CUDA深耕开发者多年,但生态重心长期聚焦云端显卡,PC端Agent 生态仍处于从零搭建阶段,缺乏面向消费级、中小企业开发者的普惠扶持政策,落地速度滞后于已经形成软硬件闭环的AMD生态。
总结:AI Agent时代,AMD依托全栈优势将会长期领跑

最后简单总结一下。放眼未来,本地AI智能体PC将持续向大众消费级市场下沉,Rahul提出“瀑布式下沉”战略:当下仅能在高端Gorgon Halo平台落地的300B大模型、多智能体集群能力,未来将逐步下放至主流锐龙AI 300/400系列的后续产品,让普通轻薄本和迷你电脑也具备本地运行中小参数智能体的能力。
行业整体将走向云端 + 本地混合算力模式:OpenAI、Anthropic 等头部大模型厂商受海量 Token成本压力,未来会主动拆分算力负载,将轻量化推理、个性化智能体部署转移至终端硬件,本地AI PC成为大模型厂商分流算力的关键载体,利好拥有全平台适配能力的AMD持续扩容市场。
短期来看,NVIDIA依托CUDA生态与微软深度绑定,有望在高端创意、专业AI开发领域占据一席之地;但中长期维度上,AMD凭借前瞻性的技术预判、X86全系统兼容的底层架构优势、覆盖全价位的产品矩阵、ROCm开源 + 全域赋能的开发者生态,在AI智能体PC全民普及浪潮中占据先发、结构性原生优势,持续巩固X86端侧本地大模型硬件龙头地位,引领AI PC从专业工具走向全民普惠时代。

智能体PC时代来临:AMD锐龙AI MAX 系列前瞻布局持续领跑
2026年6月5日 10 : 48 电脑报原创
随着AI智能体应用迎来爆发式增长,PC产业正迎来数十年一遇的颠覆性变革,传统电脑硬件的产品逻辑、使用场景伴随端侧大模型落地迎来重构,超级Agent PC正式登上行业舞台。在这一轮产业变革中,AMD凭借前瞻性研判早早落地锐龙AI Max系列产品线,NVIDIA则在时隔一年半后发布了RTX Spark入局角逐。两大巨头同台发力不仅印证端侧AI PC巨大的市场潜力,也拉开了X86与ARM两大架构在本地AI赛道的正面竞争。
AI从GPU云端推理迈入本地AI Agent新纪元
AMD表示,伴随OpenClaw、Hermes等智能体应用爆发式增长,全球AI产业正发生底层范式迁移。过去AI算力高度依赖云端数据中心GPU集群完成模型训练与推理,如今在AI Agent应用需求的驱动下,产业从单一GPU云端推理时代正式步入CPU+GPU协同运算的端侧本地智能体时代。
从NVIDIA提供的数据来看,当前80%的Token消耗量由各类AI智能体贡献,大模型参数规模持续走高、多智能体集群协同成为主流应用方向,云端Token使用成本暴涨也成为企业与开发者的普遍痛点,这些都催生了对本地高性能AI PC的刚需。由此可见AI Agent时代的到来已经是业界的共识。
根据高盛研报预测,至2030年,全球月度Token产出将达到12亿亿级别,单一企业规模化部署云端智能体的成本动辄每月数千万美元,本地端侧硬件落地大模型、分流云端算力成为行业必然选择。在此产业拐点下,AMD 与NVIDIA先后推出针对性的处理器产品,正式拉开超级Agent PC商业化落地的大幕,PC硬件的核心定位从传统办公娱乐工具,转变为可自主思考、自主完成复杂任务的个人AI协作终端。
战略远见:AMD率先锚定端侧AI赛道
早在2025年的CES展会,AMD便率先发布锐龙AI Max系列处理器,成为X86平台早期唯一能够支撑本地端运行超大参数大模型的芯片方案,可见其已经提前预判了AI智能体爆发的产业趋势,完成初代Strix Halo平台落地布局,相比NVIDIA刚刚才发布的RTX Spark提前一年多,充分印证了AMD在端侧AI与智能体主机赛道领先全行业的前瞻判断力。
AMD高级副总裁、客户端业务总经理Rahul Tikoo 在COMPUTEX 2026访谈中表示:“两年以来,我们几乎是这一领域唯一的参与者,我们在2025年CES上发布锐龙AI Max系列,产品瞄准创作者、工作站、游戏与新兴 AI 场景,经过一年多发展,已联合各大OEM落地超35款终端产品”。依托初代平台落地经验,AMD在2026年迭代第二代Gorgon Halo平台,计划于第三季度正式上市,最高统一内存规格升级至192GB,原生支持本地运行300B参数超大模型、并行部署多智能体集群,不仅远超英伟达N1X所能支持的规模,还能完整覆盖开发者、企业商用、消费级三大市场。
NVIDIA方面在2026年6月1日的GTC大会上正式发布了代号为N1X的RTX Spark 超级芯片,以Blackwell GPU + Arm架构的Grace CPU异构组合切入个人智能体PC赛道。在AMD验证端侧 AI市场价值、培育用户与生态一年多之后,NVIDIA才选择跟进入场。Rahul对此直言:“我们很高兴看到NVIDIA进入这一领域,NVIDIA实际上帮助整个行业验证了这一市场空间的价值,也让更多人意识到边缘AI和端侧AI是真实存在且具有实际意义的”。
与此同时,端侧AI市场体量足够庞大,完全可以容纳多家厂商同台竞争。Rahul明确表示,AI将实现全场景无处不在,只要存在数据就会有AI应用落地,目前整个端侧AI PC市场仍处于发展初期,未来将成长为巨型赛道,多元厂商共同入局有利于加速全产业链生态完善。AMD坦然接受行业竞争,依托自身产品与生态优势从容应对挑战。实际上,除NVIDIA外,高通骁龙C平台、英特尔Wildcat Lake、苹果M系列芯片均陆续布局定位入门的AI PC,进一步印证赛道扩容的长期逻辑。
产品深度对比:锐龙 AI Max+395 全平台兼容优势凸显
从硬件设计来看,锐龙AI Halo开发者平台使用的锐龙AI Max+ 395处理器基于成熟X86架构研发,依托数十年X86产业链积淀,可对现有Windows、主流Linux发行版实现一键原生适配,无需定制专属操作系统,现有海量Windows桌面软件、Linux开发工具、行业商用程序无需转译均可无缝迁移运行,拥有天然原生优势。
Rahul介绍,AMD长期与微软深度协同,针对微软正在迭代的Agentic OS(智能体操作系统)、AI Agent沙盒机制提前参与研发,相关系统优化功能上线时,AMD全系列产品可实现Day 0 第一时间适配,仅需OEM完成终端产品认证即可落地。
相比之下,NVIDIA的RTX Spark采用Arm架构的Grace CPU + Blackwell GPU 组合,受底层架构限制,无法兼容常规Windows,必须依赖微软专门定制的Windows on Arm专属版本,大量存量X86架构的Windows软件需要通过模拟层运行,不仅存在性能损耗,部分工业软件、商用外设驱动、传统开发工具仍面临兼容性缺失问题,跨系统部署成本远高于X86架构的锐龙 AI Halo开发者平台。
硬件配置上,锐龙AI Max+ 395搭载Zen5架构16核32线程CPU、40CU规格的RDNA3.5架构GPU、50 TOPS算力NPU,Strix Halo就已经最高可搭配128GB统一内存,新一代Gorgon Halo更是升级至最高192GB统一内存,原生硬件规格即可本地流畅运行300B超大参数大模型,支持6~10个智能体同步并行运算,实现智能体集群本地部署。
实测数据显示,运行120B GPT OSS模型时,锐龙AI Halo开发者平台推理速度较英伟达DGX Spark 高出7%;122B Qwen3.5模型领先 12%;35B Qwen3.6和30B GLM4.7 Flash分别领先4%、14%,在主流开源大模型推理场景全面占优。
NVIDIA RTX Spark方面,它拥有1 Petaflop FP4 AI算力、128GB 统一内存,没有搭载独立NPU,因此不能实现CPU + GPU + NPU三重异构算力协同,本地上限仅运行120B参数模型,在大模型承载上限方面低于锐龙的Halo家族。
产品线方面,AMD依靠统一X86平台架构打造全梯队产品矩阵,包括入门级锐龙 200系列、中端锐龙 AI 300系列、高端锐龙 AI 400系列、旗舰锐龙AI Max 300和新一代的锐龙AI Max PRO 400系列,同源架构让OEM厂商依托一套平台快速开发全价位产品,覆盖入门至高端工作站全细分市场,搭配AMD PRO技术,打通消费、中小企业、大型政企全渠道。
相比之下,RTX Spark产品定位高度集高端市场,产品仅面向高端创作者与专业开发者,缺少入门、中端产品线布局,难以下沉主流平价PC市场,对比AMD全平台产品布局存在明显短板。
软件生态部分,AMD以ROCm开源软件栈全框架Day0适配为核心构建软件生态,实现从云端数据中心到端侧PC全链路无缝兼容 PyTorch、ComfyUI、vLLM 等主流AI框架,大幅降低跨场景部署成本。针对锐龙 AI Halo开发者平台,AMD预置5套开箱即用Playbook开发手册,后续新增至 10 套,彻底解决开发者过去耗费数天调试Claw、各类 AI框架环境的痛点;软件完成优化和平台验证后,全量下放至合作伙伴全系列锐龙AI Max产品,普惠全品类终端用户。
开发者是AI Agent PC产业落地的核心根基,AMD在开发者扶持层面也落地实质性举措,构建从线下会议、云端资源、软硬件工具的全链条赋能体系,近期AMD 在上海成功举办AI开发者日,成为国内开发者生态建设关键里程碑。
Rahul在访谈中提及,AMD 高管、软件团队常态化对接全球数百名开发者,在多地举办开发者日,现场开放产品沙盒试验环境,让开发者免费实测锐龙AI全系列硬件,这就类似AMD在成熟游戏领域的 FSR生态合作经验,将深度协同开发者的基因复制至AI领域。
在落地细则上,加入AMD开发者计划即可免费申领云端算力Token、持续获取BKC最优配置软件更新、享受原厂技术团队一对一支持;OEM厂商同步推出标准化锐龙 AI Halo 硬件盒子,统一软件镜像,帮助开发者低成本批量部署本地AI节点。
从商业落地角度来看,锐龙 AI Halo 可以帮助企业大幅削减云端Claude Code等智能体工具的巨额 Token 开支,这一经济性优势快速收获政企CIO认可,倒逼OpenAI、Anthropic等闭源大模型厂商探索“云端 + 本地混合部署”新模式,为AMD平台拓展更大商用空间。
相较之下,NVIDIA虽凭借CUDA深耕开发者多年,但生态重心长期聚焦云端显卡,PC端Agent 生态仍处于从零搭建阶段,缺乏面向消费级、中小企业开发者的普惠扶持政策,落地速度滞后于已经形成软硬件闭环的AMD生态。
总结:AI Agent时代,AMD依托全栈优势将会长期领跑
最后简单总结一下。放眼未来,本地AI智能体PC将持续向大众消费级市场下沉,Rahul提出“瀑布式下沉”战略:当下仅能在高端Gorgon Halo平台落地的300B大模型、多智能体集群能力,未来将逐步下放至主流锐龙AI 300/400系列的后续产品,让普通轻薄本和迷你电脑也具备本地运行中小参数智能体的能力。
行业整体将走向云端 + 本地混合算力模式:OpenAI、Anthropic 等头部大模型厂商受海量 Token成本压力,未来会主动拆分算力负载,将轻量化推理、个性化智能体部署转移至终端硬件,本地AI PC成为大模型厂商分流算力的关键载体,利好拥有全平台适配能力的AMD持续扩容市场。
短期来看,NVIDIA依托CUDA生态与微软深度绑定,有望在高端创意、专业AI开发领域占据一席之地;但中长期维度上,AMD凭借前瞻性的技术预判、X86全系统兼容的底层架构优势、覆盖全价位的产品矩阵、ROCm开源 + 全域赋能的开发者生态,在AI智能体PC全民普及浪潮中占据先发、结构性原生优势,持续巩固X86端侧本地大模型硬件龙头地位,引领AI PC从专业工具走向全民普惠时代。
分享到:
评论区(0条)
本文作者
电脑报编辑
认真是一种态度
推荐文章
更多文章